✍🏻 나노바나나란?
나노 바나나는 사실 코드명이고, 정식적으로는 구글이 제공하는 '생성형 이미지 모델' 라인업의 이름이다. 정확한 명칭은 Gemini 2.5 Flash Image 모델이라고 볼 수 있다.
이 모델의 핵심은 단순히 이미지를 생성하는 것을 넘어서 네이티브 멀티모달 아키텍처를 가지고 있다는 점이다.
텍스트와 이미지를 하나의 통합된 단계에서 처리하도록 처음부터 훈련되어있다.
👩🏻💻 원리를 조오금 뜯어보자
✔️✍🏻 기존에는 텍스트와 이미지, 참고 이미지를 각각 따로 이해해서 맨 마지막에만 대충 섞는 Late fusion 구조였기 때문에
'이 사람을 이 배경에 자연스럽게 넣어줘' 라는 복잡한 요구를 토큰 단위에서 충분하게 이해하기 어려웠으나,
나노바나나는 텍스트와 여러 장의 이미지를 처음부터 하나의 토큰 시퀀스로 만들어 한 Transformer 안에서 끝까지 같이 돌리는 early fusion 네이티브 멀티모달 아키텍쳐를 사용하기 때문에 그럴듯한 편집을 '한번에' 할 수 있게 되었다!!!
즉 조금 더 쉽게 말하면
기존에는 이미지를 잘~ 생성하는 모델과 이미지를 편집!하는 모델이 따로 있었으나,
생성하는 모델은 예쁜 이미지를 만들 수는 있었으나 실제로 활용하기는 어려웠고, 편집 모델은 이미지를 수정할 수는 있었으나 제한적이었다. 하지만 나노바나나는 이 두가지 기능을 융합했고 제미나이 모델의 기본 지능까지 결합했기 때문에
더욱 완벽한 이미지 생성 및 편집이 가능한 것!
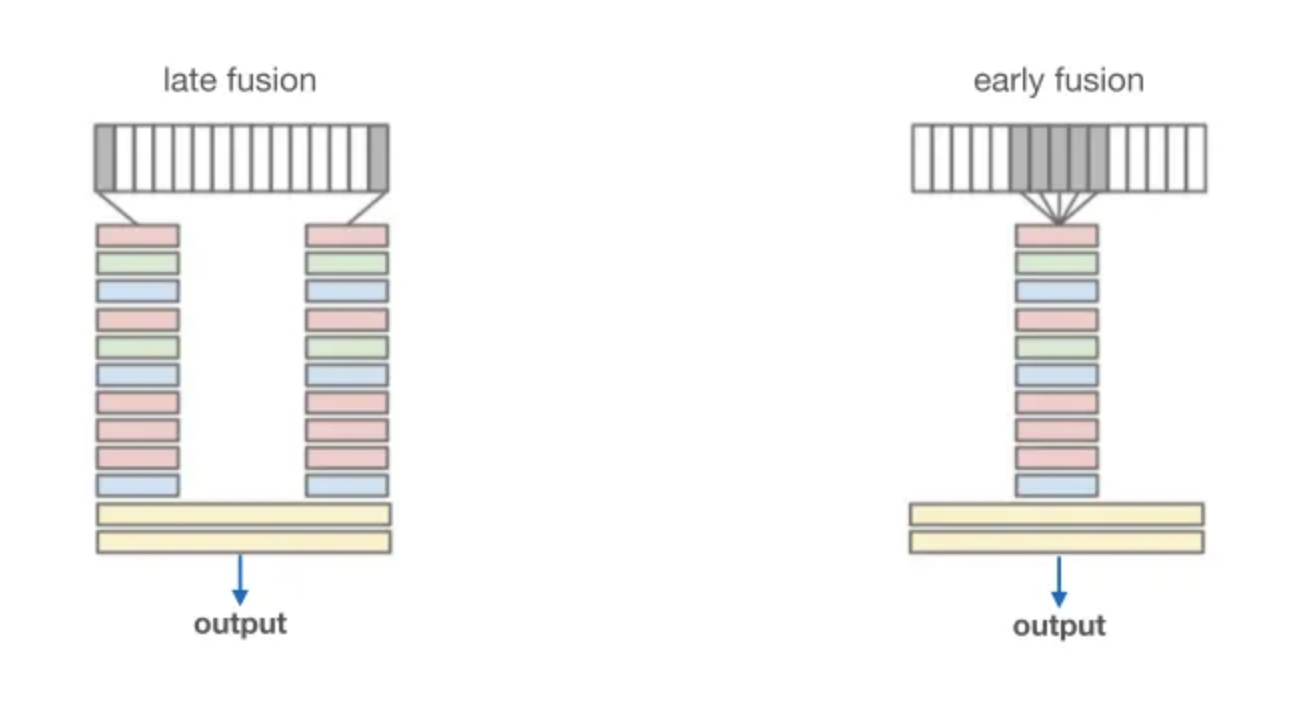
기존 이미지 생성/편집 모델 (예: 초기 Imagen 계열, Stable Diffusion 기반 편집기 등)은 대체로 late fusion 계열로 구분한다.
텍스트 인코더와 이미지 인코더를 통해,
텍스트는 텍스트대로, 이미지는 이미지대로 몇 층을 타며 고차원 feature로 변환되고,
마지막에 diffusion UNet안에서 벡터로 합치거나 두 이미지의 최종 latent를 섞어버리는 식이었다.
이 설계의 문제점은 각 모달리티가 따로 놀다가 거의 끝에서만 만나기 때문에
- “1번 사진의 인물을 2번 사진 거실에 앉히고, 조명은 2번 사진 기준으로 맞추고, 얼굴은 1번 사진이랑 완전히 동일하게” 같은 복잡한 요구를 이해해도,
- 실제 네트워크 안에서는 “누가 누구인지, 조명과 구도가 각 이미지 안에서 어떻게 배치돼 있는지”를
토큰 수준에서 서로 맞물리게 학습할 기회가 적게 된다!!!
결과적으로......
- 캐릭터 일관성 유지 실패
- “첫 번째 사진의 조명 스타일을 유지한 채 두 번째 사진의 구도에 맞춰줘” 같은 미묘한 컨텍스트 이해 미흡
- 여러 장의 이미지를 섞을수록 이상한 콜라주 느낌, 어색한 경계, 그림자/원근 오류
같은 한계를 많이 보였고,
실제로 나노바나나 개발자도 “이전에는 생성 모델과 편집 모델이 따로라 실사용하기 애매했다”고 말했다!
✏️ 그렇다면....나노바나나는?
토큰 단계에서부터 한 세계로 만들게 된다.
나노바나나가 하는 건 한 줄로 요약하면 “텍스트와 여러 장의 이미지를 전부 같은 토큰 시퀀스로 만든 뒤,
하나의 거대한 Transformer 안에서 처음부터 끝까지 같이 돌린다”
모든 텍스트 입력을 토큰으로 쪼갠 뒤,
각 이미지는 Vision Transformer 스타일로 패치 단위(예: 16×16 픽셀)로 나눠서
discrete image token 혹은 patch embedding으로 바꾼다
(복잡한 말이지만 쉽게 말하면!)
여러 이미지를 넣으면 [이미지1 패치들] [이미지2 패치들] … [텍스트 토큰들] 같이 하나의 긴 시퀀스로 이어붙이게 되어
Transformer가 토큰 간의 관계를 구분할 수 있게 된다.
즉 하나의 Transformerrk 가 통과시키기 때문에
정보를 한꺼번에 정렬시키게 된다.
이때 각 층의 attention head는
“2번 이미지의 소파 패치”가
“1번 이미지의 사람 실루엣 패치”,
“텍스트 ‘노란 니트’, ‘오른쪽 끝 소파’ 토큰”
을 동시에 바라보면서,
하나의 멀티모달 latent가 생기고 한꺼번에 공간적으로 풀어내게 된다.
즉, 텍스트는 텍스트대로, 이미지는 이미지대로 자기 네트워크를 끝까지 타고 올라가고,
거의 맨 마지막 층에서야 “아 맞다 우리 멀티모달이었지?” 하면서 둘을 을 합치는 구조가 late fusion,
나노바나나는 텍스트와 이미지를 하나의 통합된 단계에서 처리하는 네이티브 멀티모달 아키텍처라고 이해할 수 있다.
즉 late fusion은 각 이미지가 독립 인코더를 타고 들어가 버려서, “이 토큰이 어제 그렸던 그 사람과 같은 사람이다”
라는 연결고리가 약하다 ㅠㅠ.
하지만! early fusion에서는 같은 사람의 얼굴 패치들이 계속 한 시퀀스 안에 등장하니까, Transformer가“이 눈썹 모양 + 코 각도 + 턱선 패턴 = 같은 identity”를 반복해서 학습할 수 있고,
새로운 장면을 생성할 때도 동일한 identity 벡터를 참조하게 되는 것이다.
- GPT
- 중심은 텍스트 이해·생성·추론.
- 이메일, 기획서, 코드, 스크립트, 전략 문서, 분석 리포트, 프롬프트 설계 등 “언어”가 중심인 일에 강하다.
- 이미지도 만들 수 있지만(예: DALL·E 연동), 주력은 여전히 언어 쪽!!!.
- 나노바나나
- 중심은 이미지 생성·편집
- 텍스트를 잘 이해하는 건 “이미지를 잘 만들기 위한 수단”이고,
- 궁극적인 아웃풋은 항상 시각(이미지)라고 이해할 수 있다.
✏️ 특징은???
그래서 정확히 어떤 특징들을 가지고 잇냐면!
- 텍스트+이미지 기반 생성·편집 모델
- 캐릭터·브랜드 일관성에 특화
- 텍스트 렌더링이 강함
- 에코시스템 통합
🥙 한입 AI 레시피: Gemini로 디지털 광고 시안 만들기 (a.k.a 나노 바나나)
Gemini 2.5 Flash Image로 1분 만에 광고 시안을 만드는 방법을 소개합니다
modulabs.co.kr
요 링크에서는 디지털 광고 시안을 만드는 방법을 작성해주고 있으니
참고해도 좋을 듯하다!
프롬프트 설명 :
도심 버스 정류장 광고판에 사용할 소형 여행 카메라 광고를 제작하세요.
장면: 실제 도시 거리의 버스 정류장, 실제 광고 프레임이 설치된 모습.
환경: 가로등이 켜진 저녁 분위기, 도시 건물과 자연스러운 야외 환경. 가시성: 야외 시청 조건에 최적화된 고대비 디자인.
광고 디자인:
- 배경: 밝은 파란색에서 짙은 파란색으로 이어지는
그라데이션 - 중앙 비주얼: 첨부된 둥근 파란색 캐릭터와 카메라 이미지를 그대로 사용하세요.
캐릭터나 카메라를 재디자인하지 마세요.
- 텍스트 배치: 상단 중앙에 헤드라인을 두 줄로 배치하세요.
1줄: "TRAVEL LIGHT,"
2줄: "FEEL BRIGHT."
그 아래에 `"Your Journey, Simplified."` (중간 크기의 흰색 텍스트)를 배치하세요.
- 물결 패턴: 캐릭터 뒤쪽에서 오른쪽 위로 흐르며 헤드라인 텍스트와 겹치지 않도록 배치하세요.
스타일: 깔끔하고 미니멀하며 프리미엄한 느낌.
실제 도심 버스 정류장에 전문적으로 설치된 광고처럼 보이고, 자연스러운 도시 조명과 사실적인 원근감을 반영하세요.

프롬프트는 어떤 식으로 작성할까?
나노바나나는 “키워드 나열”보다 짧은 문장으로 장면을 설명해주면 성능이 더 잘 나온다는 팁이 한국 블로그·강의에서 공통적으로 등장하고 있다.
프롬프트를 쓸 때는:
- 누가(Who) – 인물의 나이, 성별, 스타일
- 어디서(Where) – 배경(실내/실외/도시/자연/매장 등)
- 무엇을(What) – 어떤 행동/제품/상황
- 어떤 느낌으로(Style) – 사진/일러스트/수채화/3D/레트로/키치 등
- 어디에 텍스트를(Design) – “상단 중앙에 ‘OOO’ 문구”, “우측에 제품 설명 박스” 등
- 비율·용도 – “9:16, 인스타 릴 썸네일용”, “16:9, 유튜브 썸네일용” 등
예를 들어 비타민 광고라면:
“30대 초반 한국인 여성 모델, 흰 셔츠와 재킷을 입고 밝게 웃으며 책상 위 비타민 병을 들어 보이는 장면. 배경은 밝은 병원 진료실 느낌. 상단에는 ‘하루의 시작, OOO 비타민’이라는 한글 텍스트를 굵고 깔끔한 폰트로 넣어줘. 4:5 비율 인스타 피드 광고용, 사진 스타일로.”
요즘 현업에서는
GPT로 콘셉트·카피·프롬프트 → 나노바나나로 이미지 → 다시 GPT로 성과 분석/테스트 아이디어
이런 식으로 활용하는 것이 많이 쓰이고 있다고 한다.
👩🏻💻📌👀 흠... 나노바나나를 활용해서 직접 만들어보자!


..더 흔들라고 했더니
그냥 눈을 감아버려서 아쉬웠다.


골반통신 자체를 좀 이상하게 이해한 것 같기는 하지만....
일관성 있게 <더 흔드는 것 같은> 모습을 보여주는 것 같아 신기했다.
지피티가 생성해준 지피티는 이미지 자체는 고퀄리티였으나
<더 흔들어줘> 라는 문구를 한번 더 요구하니까 배경도 달라지고 더 흔드는 것 같은 느낌도 안났는데
재미나이가 만들어준 이미지는 확실히 기존 이미지에서 더 개선된 것 같은 이미지가 완성되어 신기했다.
다음번엔 직접!! 내 서비스에 나노바나나를 사용해봐야겠다. ......!!!!!
'AI' 카테고리의 다른 글
| [AI] 2026 AI 트렌드는 어떻게 될까? (1) | 2026.01.12 |
|---|---|
| [AI] 오늘의 집 사례로 알아보는 RAG 서비스 (0) | 2025.12.14 |
| [AI] 검색(1)-이커머스 AI에이전트 (0) | 2025.11.12 |
| [AI] AI 검색 최적화, GEO 이해하기! (0) | 2025.11.02 |